 ChatGPT
ChatGPT Vet, braakbal of heerlijk? Van AD Oliebollentest naar data science-project





Sommige data science-projecten worden op bijzondere momenten bedacht. Want waarom zou de jaarlijkse AD Oliebollentest, die 28 december is gepubliceerd, interessant zijn voor een data science-project? Omdat we het ‘vet’ vinden. Maar ook om aan te geven dat je moet samenwerken met mensen uit verschillende disciplines om het maximale uit data te halen. Dit artikel geeft een beschrijving hoe data scientists binnen Cendris dit traject hebben aangevlogen en welke stappen doorlopen zijn.
Samenwerken essentieel voor data-succes
Data science-projecten ontstaan vaak vanuit strategische keuzes van het management. Maar zij kunnen ook ontstaan vanuit medewerkers met gelijke interesse in (big) data of data science. Waar vroeger de data-analist of databasemarketeer vooral een eenpitter was, is data science nu een specialisatie dat in teamverband tot de meeste successen leidt. Samenwerken en het herkennen en benutten van elkaars specialisatie is daarbij essentieel.
Om te bepalen welke ‘vette’ inzichten uit de AD Oliebollentest te halen zijn, moeten allereerst collega’s ook beschikbaar zijn. Dit is eenvoudig via een WhatsApp-groep of e-mail te polsen. En zodra er twee mensen enthousiast zijn, volgt de rest al snel. Natuurlijk is er geen tijd, maar als dit zo’n leuk en uitdagend project is, wordt zonder probleem de vrije tijd hiervoor ingezet.
Het begint met data scrapen
De eerste (en grootste) uitdaging is om alle data van de AD Oliebollentesten te scrapen. Scrapen is het automatisch omzetten van online informatie van websites in een (gestructureerde) spreadsheet. Omdat de resultaten van de AD Oliebollentest al meerdere jaren op dezelfde manier online weergeven worden en het html er goed uitziet, is het met hetzelfde script te scrapen. Voor deze klus is het vooral de programmeur die deze klus moet klaren.
Magic Marc, zo noem ik mijn collega die kan toveren met alle ruwe en online data, had dit binnen no time voor elkaar en na verdere databewerkingen en combineren van data was er een bestand beschikbaar met alle boordelingen, cijfers en motivaties van de jury van de jaren 2011 tot en met 2015.
Belangrijk fun-element: de beoordelingen
Vooral het lezen van de motivaties van de jury draagt bij aan het fun-element. Beschrijvingen als “Massieve kanonskogels waarmee je iemand de hersens kunt inslaan” en “Onvervalste braakballen! Walgelijk. Ruikt zuur” zijn voorbeelden daarvan. Niet onbelangrijk.
En dan wordt het echt leuk, want nu kunnen hypotheses opgesteld worden. Dit is de tweede stap binnen een data science-project. Hoe diverser hoe beter, want op een later moment toetst de data-analist of het significant is. Uit de eerste verkenning:
- Waar betaal je het meeste vet?
- Waar vind je de biologische bal?
- Waar krijg je veel voor weinig?
- En waar krijg je weinig voor veel?
- Hoe kom of blijf je aan de top?
- Wie is de grootste stijger en daler over de jaren heen?
- Wie heeft er wel of niet geleerd van de slechte beoordeling?
Maar de belangrijkste vraag was of we de winnaar van 2015 kunnen voorspellen. We kwamen al snel tot de conclusie dat het aantal beschikbare variabelen en de kans op afbreukrisico te groot was, omdat het juryoordeel net teveel het verschil kan maken. Daarom hebben we gekozen om een aantal andere vragen te onderzoeken. Met de software ‘R’ hebben we grafieken gemaakt voor het visueel inzichtelijk maken van de hypotheses. Dit werkt erg snel en flexibel, maar dan moet je wel goed met deze tool kunnen omgaan.
Eenvoudige weergave belangrijk om data inzichtelijk te maken
Na de derde stap, het analyseren, komt de fase van het visualiseren en presenteren van de resultaten. Het denken vanuit de lezer is hierbij erg belangrijk. En veelal is een eenvoudige weergave veel sterker dan een infographic waar veel tijd ingestoken is. Dit heeft geleid tot de volgende interessante inzichten.
Het lezen van de jurybeoordelingen is leuk, maar is er een verband uit te halen? Met een gemaakte tagcloud van de beste (cijfer 8 en hoger) en slechtste (cijfer 3,5 en lager) beoordelingen komt de herkenning al snel weer terug.

Oliebollen met goede beoordelingen…

…en slechte beoordelingen
Wie is ‘oliedom’?
We hebben ook onderzocht wie geleerd heeft van een slechte beoordeling. We hebben hierbij alleen gekeken naar verkooppunten met beoordelingen over meerdere en aaneengesloten jaren, want alleen dan is er sprake van leereffect. Voor de leesbaarheid hebben we alle beoordelingen ingedeeld in ‘slecht’, ‘gemiddeld’ en ‘goed’ en vastgesteld hoe oliebollenverkopers zich hebben ontwikkeld in de tijd.
In onderstaande figuur is af te lezen wie zijn gedrag heeft aangepast. De grootste groep is gelijk gebleven met score gemiddeld tot goed (64 procent). Maar ook bijna 8 procent was slecht en heeft er nog steeds niet van geleerd. Ook 9 procent van de onderzochte verkooppunten is achteruit gegaan. Conclusie is dat driekwart van de verkooppunten vooruit is gegaan en minimaal oliebollen verkoopt die gemiddeld tot goed worden beoordeeld.
| Eerste beoordeling | |||
|---|---|---|---|
| Laatste beoordeling | Goed | Gemiddeld | Slecht |
| Goed | 20% | 11% | 2% |
| Gemiddeld | 8% | 44% | 6% |
| Slecht | 0% | 2% | 8% |
| Verbetering | 19% |
| Gelijk gebleven | 64% |
| Slechter | 9% |
| Oliedom | 8% |
Waar in mijn buurt moet ik oliebollen gaan kopen?
Omdat visualisaties altijd erg overtuigend werken en tot detailniveau de meeste relevante gegevens kunnen tonen, hebben wij een interface gemaakt waarmee je interactief kunt bepalen waar je moet zijn voor de beste oliebol. We hebben data van de periode 2011-2014 gebruikt en afgelopen maandag ook de gegevens van 2015 toegevoegd. Op deze manier weet je waar je de beste oliebollen moet halen voor jouw data-analisten of databasemarketeers om ze te bedanken voor hun inzet het afgelopen jaar en zij volgend jaar weer het maximale uit alle data zullen gaan halen.
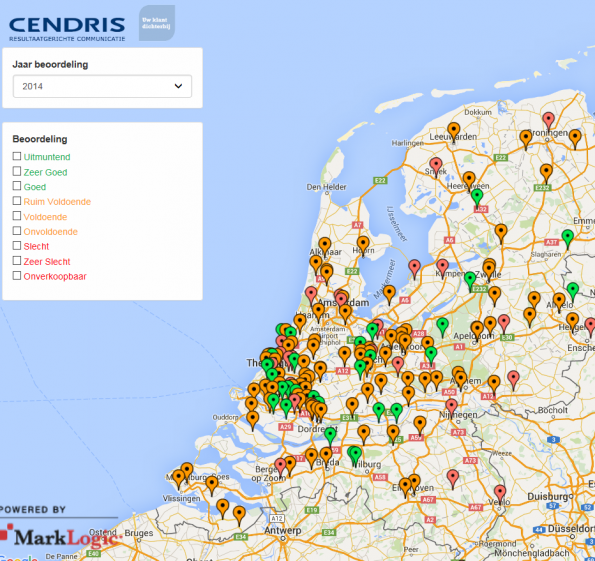
Hier vind je de visualisatie
Bovenstaande interface hebben wij met MarkLogic gebouwd. MarkLogic is een enterprise ready no-SQL-platform dat organisaties en data scientists in staat stelt om via een agile opzet succesvol en snel data te laden en waar nodig te bewerken. Verschillende datatypes en formaten die voorheen alleen via langdurige ETL-processen met elkaar konden worden verbonden, verbindt MarkLogic zonder handmatige aanpassingen.
Data science is samenwerken
Met een project als dit leer je samen te werken met de mensen die data science-projecten succesvol kunnen maken binnen een organisatie. Ieder heeft zijn eigen specialisme en alleen zo haal je het maximale uit de data zelf.
Je leert ook met welke aanpak en tools je het maximale resultaat kunt behalen. Voor dit project hebben we behoorlijk wat verschillende software gebruikt. Het goed werken met verschillende tools is een van de onderdelen van de data science-‘gereedschapskist’.
Start zelf een project
Veel bedrijven zijn nog zoekende naar de invulling van hun data science journey. Start zelf een project zoals dit om mensen binnen de organisatie te verbinden, ook al zitten ze niet op dezelfde afdeling. Dan zul je merken dat jouw afdeling of team vaker gevraagd wordt voor het echte data science-werk.
Nog nieuwsgierig naar bepaalde inzichten? Laat een berichtje hieronder achter. We reageren zo snel mogelijk, mits we niet in de rij staan bij een van de beste oliebollenkramen.
Afbeelding intro via Fotolia
Over de auteurs



