
Het brein van ChatGPT: hoe AI-modellen context ‘leren begrijpen’


Sinds de lancering van ChatGPT leek het alsof de wereld van kunstmatige intelligentie plotseling een enorme, bijna magische sprong voorwaarts had gemaakt. Wat veel mensen niet weten, is dat de oorsprong van deze ‘magie’ teruggaat tot het jaar 2017. Toen introduceerde een paper genaamd: “Attention is All You Need” het cruciale ingrediënt dat deze technologie zo effectief maakt: Transformers.
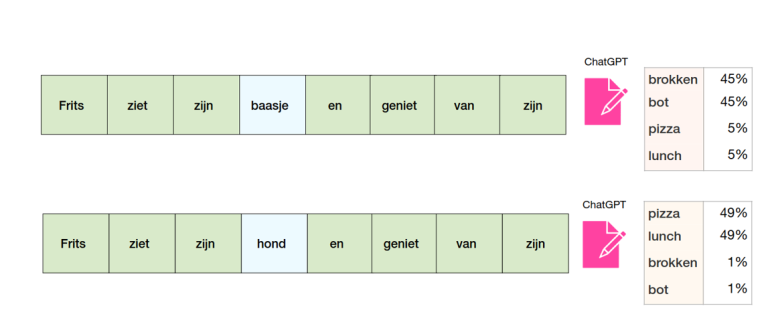
In dit artikel ga ik op een intuïtieve wijze de werking van Transformers ontleden. Om er vervolgens achter te komen dat er weinig magie aan te pas komt. Laten we beginnen met een voorbeeld waarbij we ChatGPT vragen om de volgende zinnen aan te vullen. En daarbij meerdere opties aan te bieden met hun bijbehorende kansen:
Mens, wetenschapper en AI-modellen
Simpel gezegd, berekent ChatGPT het eerstvolgende ‘logische’ woord. Klinkt eenvoudig, nietwaar?
Voor ons mensen wel. Maar voor wetenschappers is het een hele uitdaging om een AI-model te ontwikkelen dat deze taak even effectief kan uitvoeren als wij mensen. Kijk maar waar we allemaal op moeten letten. En wat er gebeurt als er kleine veranderingen plaatsvinden:
- In de eerste zin is het woord “baasje” relevant om te kunnen bepalen dat Frits waarschijnlijk een hond is die ergens van geniet.
- In de tweede zin is het woord “hond” niet zo relevant, en kan het beter worden weggelaten als we Frits in de context willen plaatsen van een persoon die ergens van geniet.
Als ik je over een langere periode zou vragen om één van bovenstaande zinnen woord voor woord te reproduceren, dan zul je hier wat moeite mee hebben. Maar als ik de vraag stel: wie was er aan het genieten, het baasje of de hond? Dan is de opgave een stuk makkelijker.
Het aandacht-mechanisme
Dit komt doordat we niet evenveel aandacht hoeven te schenken aan elk woord in de zin. En doordat we woorden grotendeels kunnen negeren, zonder dat dit ten koste gaat van de context. Maar dit voorbeeld toont ook aan dat kleine verschuivingen en/of nuances van cruciaal belang zijn om te snappen wat er precies gaande is.
Maar hoe kunnen we een AI-model trainen dat hiertoe in staat is? Wat we eigenlijk nodig hebben is een soort van aandacht-mechanisme dat, net zoals bij menselijke taalverwerking, in staat is om de belangrijke en relevante woorden te identificeren en hier de focus op te leggen. Voordat we hierop inzoomen, is het van belang dat we eerst begrijpen hoe AI-modellen met taal omgaan. Omdat zij niet direct in staat zijn om menselijke taal te verwerken zoals wij dat doen. In plaats daarvan wordt taal omgezet in de enige vorm die voor hen begrijpbaar is: getallen.
Van woorden naar getallen
AI-modellen kunnen menselijke taal niet direct verwerken. In plaats daarvan moeten ze de woorden ‘vertalen’ in iets dat zij wel kunnen begrijpen – getallen.
Je kunt dit voorstellen als het in kaart brengen van elk woord naar een unieke reeks van getallen. Nadat de woorden in getallen zijn veranderd, begint het model te kijken naar de volgorde en de relatie tussen deze getallen. Het probeert te begrijpen welke getallen (woorden) belangrijker zijn dan andere in een bepaalde context.
In een boek lees je bijvoorbeeld niet elk woord met evenveel aandacht. Sommige woorden zijn belangrijker voor het begrijpen van het verhaal dan anderen. De AI werkt op een soortgelijke manier. Het model bepaalt welke ‘getallen’ meer aandacht nodig hebben dan andere, om de betekenis van de zin te begrijpen.
Maar hoe doet het model dit? Hoe weet het model welk ‘getal’ belangrijker is dan het andere? Precies daar komt die beroemde paper “Attention is All You Need” in het spel. Het introduceerde het concept van de ‘Transformer’ – het aandacht-mechanisme dat dit allemaal mogelijk maakt.
De Transformer
Transformers vormen het fundament onder AI-modellen zoals ChatGPT. Ze werken op basis van het principe dat ze aandacht schenken aan woorden op basis van hun context. Stel, we hebben een voorbeeldzin: “Waar is de hond?”
De woorden worden eerst verwerkt tot getallen en gaan dan door een proces dat bekend staat als tokenisatie. Denk eraan als het hakken van de zin in stukjes (tokens). Elk van deze stukken krijgt een uniek getal dat in kaart wordt gebracht naar het corresponderende woord. Hierdoor wordt de zin omgezet in een vorm die begrijpelijk is voor het AI-model:
 Na het proces van tokenisatie worden de tokens, nu gerepresenteerd als getallen, omgezet in wat we token embeddings noemen. Dit gebeurt in een zogenaamde embeddinglaag, die deze getallen omzet in vectorrepresentaties (een vector is niets meer dan een reeks getallen) die de semantische betekenis van de tokens bevatten. Kortom, deze embeddings veranderen woorden in een vorm die de computer kan begrijpen. En niet zomaar begrijpen, maar begrijpen in een manier die de onderlinge relaties en betekenissen van woorden vangt.
Na het proces van tokenisatie worden de tokens, nu gerepresenteerd als getallen, omgezet in wat we token embeddings noemen. Dit gebeurt in een zogenaamde embeddinglaag, die deze getallen omzet in vectorrepresentaties (een vector is niets meer dan een reeks getallen) die de semantische betekenis van de tokens bevatten. Kortom, deze embeddings veranderen woorden in een vorm die de computer kan begrijpen. En niet zomaar begrijpen, maar begrijpen in een manier die de onderlinge relaties en betekenissen van woorden vangt.
Dit is het moment waarop de Transformer zijn rol begint te spelen. De tokens, nu gerepresenteerd als embeddings, worden aan het model geleverd. Het is bij deze stap dat het hele proces begint met iets dat ‘self-attention’ wordt genoemd.
Self-attention
Self-attention is het concept dat het model in staat stelt te bepalen welke woorden in een zin meer met elkaar te doen hebben. Als voorbeeld, in de zin “De hond speelt in het park”, liggen ‘hond’ en ‘speelt’ dichter bij elkaar dan ‘hond’ en ‘park’. Dankzij het self-attention-mechanisme kan het model deze onderlinge relaties detecteren.
Vervolgens richt het model bij het genereren van de output zijn aandacht niet alleen op de huidige en vorige woorden, maar doet het ook voorspellingen op basis van de verzamelde informatie tot nu toe. De transformer suggereert verschillende mogelijke volgende woorden en bepaalt hoe geschikt elk voorgesteld woord is in de gegeven context.
Maar hoe werkt Self-attention dan?
Self-attention stelt modellen in staat om woorden in een zin te relateren aan elkaar. Elk woord in de zin kan contextuele informatie ontlenen aan elk ander woord. Neem bijvoorbeeld wat we al eerder gezien hebben: “Frits ziet zijn baasje en geniet van zijn…”. Hier zal het self-attention-mechanisme elk woord in relatie tot ‘zijn’ evalueren.
En dit werkt zo: het model berekent een aandacht-score voor hoe relevant elk ander woord in de zin is voor ‘zijn’. Het model begrijpt dat ‘Frits’ en ‘baasje’ een sterke relatie hebben met ‘zijn’, omdat ‘zijn’ kan verwijzen naar zowel ‘Frits’ als ‘baasje’ afhankelijk van de context. Deze aandacht-scores helpen het model bij het opbouwen van een semantisch begrip van de zin en het correct voltooien ervan.
Hoe wordt deze aandacht-score berekend?
Elk woord wordt gerepresenteerd door drie vectoren: een Query-vector, een Key-vector en een Value-vector. Deze vectoren worden tijdens het trainingsproces geleerd en bijgewerkt.
Een eenvoudige manier om de Query-, Key-, en Value-vectoren te begrijpen, is door dit te vergelijken met een proces van online winkelen.
Stel je voor dat je online op zoek bent naar een bepaald product, bijvoorbeeld ‘hardloopschoenen’ (je Query). De Key wordt dan gezien als de productbeschrijvingen of kenmerken die aan elk item zijn toegewezen. Sommige items hebben kenmerken zoals ‘hardloopschoenen’, andere hebben ‘sandalen’, ‘laarzen’, enz. Wanneer je Query (‘hardloopschoenen’) overeenkomt met een Key (‘hardloopschoenen’), dan krijgt die overeenkomst een hoge score.
De Value kun je zien als het eigenlijke product dat gekoppeld is aan die kenmerken. Dus, wanneer ‘hardloopschoenen’ (je Query) overeenkomt met een Key (‘hardloopschoenen’), dan krijg je een product (Value) dat precies datgene is waar je naar op zoek was.
Terug naar onze transformer
De Query-vector van een woord wordt gebruikt om te ‘vragen’ hoeveel aandacht elk ander woord moet krijgen. De Key-vector van een ander woord wordt gebruikt om te ‘antwoorden’ op deze vraag door een overeenkomstig gewicht te geven op basis van de relatieve betekenis. De Value-vector wordt gebruikt om de inhoud van het woord te belichamen.
Bij het berekenen van de aandacht-scores, analyseert het model hoe goed de Query (je vraag) overeenkomt met elke Key (labels) in de zin, en geeft vervolgens meer gewicht aan de Values (inhoud) van die overeenkomsten.
In de praktijk wordt de aandacht-score berekend door de Query-vector van het focuswoord te vermenigvuldigen met de Key-vector van elk ander woord. Deze score wordt vervolgens gebruikt om de Value-vectoren te wegen, een soort van gewogen gemiddelde op te bouwen, waardoor het model zich kan concentreren op belangrijkere woorden. Deze gecombineerde waarde wordt vervolgens doorgegeven aan de volgende fase van het transformer-model, waarbij het model de selectie van het volgende woord in de sequentie bepaalt.
Het trainingsproces van transformer-modellen
Het trainingsproces van transformer-modellen is grotendeels een leerspel van proberen, aanpassen en opnieuw proberen op grote schaal. Eerst hebben we een grote hoeveelheid tekstdata nodig, die vaak afkomstig is van diverse bronnen op het internet. Dit wordt de “trainingsdata” genoemd.
Het trainingsproces begint met het randomiseren van de gewichten van het model, wat inhoudt dat ze op dat moment in feite niets betekenen. Vervolgens begint de toevoer van de trainingsdata – zin voor zin, woord voor woord. Voor elke invoer voorspelt het model de volgende woorden (of “tokens”) in de reeks op basis van de tot dusver geziene tekst. Aangezien de gewichten in het begin willekeurig zijn ingesteld, zijn deze voorspellingen in eerste instantie meestal verre van correct.
Fouten minimaliseren
Na elke voorspelling, evalueert het model hoe nauwkeurig het was. Dat doet het model door de voorspelde woorden te vergelijken met de daadwerkelijke volgende woorden in de inputreeks. Dit verschil, of deze afwijking, wordt “loss” of “verlies” genoemd.
Het doel van het trainingsproces is om deze fout te minimaliseren. Dit gebeurt via een proces genaamd ‘backpropagation’. Bij backpropagation wordt de fout teruggestuurd door het model, laag voor laag, en worden de gewichten van het model op basis van die fout aangepast. Dit zorgt ervoor dat het model de volgende keer betere, nauwkeurigere voorspellingen kan doen.
Dit proces wordt miljoenen malen herhaald. Daarbij worden met elke iteratie de gewichten van het model een beetje meer ‘afgestemd’ op de complexiteiten van menselijke taal. Zo kan het na verloop van tijd heel goed de volgende woorden in een tekst voorspellen, waardoor het teksten kan genereren die menselijk overkomen. Dit verfijnde model wordt vervolgens opgeslagen en gebruikt om uiteindelijke voorspellingen te doen. Denk aan het genereren van een tekst in reactie op een bepaalde prompt (invoer).
Menselijke taal leren en begrijpen
Samenvattend, transformer-gebaseerde modellen zoals ChatGPT en Bard zijn revolutionaire tools in het veld van natuurlijke taalverwerking. Ze benutten geavanceerde technieken zoals ‘self-attention’ om contextuele associaties tussen de woorden in een zin te begrijpen. Hierdoor kunnen deze modellen menselijke taal op een zeer effectieve manier genereren en begrijpen.
Het trainingsproces van deze modellen is intensief en omvat het constante itereren, aanpassen en afstemmen van gewichten op basis van grote hoeveelheden tekstdata. Hoewel dit proces complex en rekenkundig intensief is, stelt het deze modellen in staat om de subtiele nuances van menselijke taal te leren en te begrijpen.
In conclusie, de transformer-architectuur en de erop gebaseerde modellen hebben de manier waarop we naar taalmodellering en generatie kijken veranderd. Ze hebben de mogelijkheid opengesteld om interactieve AI’s te creëren die coherente en contextueel relevante tekst kunnen genereren. En dat maakt tal van toepassingen mogelijk. Van chatbots en schrijfhulpmiddelen tot klantenservice en meer. Hoewel er nog steeds uitdagingen en vraagstukken zijn, met name op het gebied van ethiek en AI-begrip, is de vooruitgang die geboekt is onmiskenbaar indrukwekkend.
Over de auteur
