
TikTok, LinkedIn & Twitter gebruiken robots.txt verkeerd (en jij misschien ook)


Het robots.txt-bestand is een simpele, maar krachtige tool voor SEO. Het laat toe om het crawlgedrag van zoekmachines (Google, Bing) en bots te sturen. Haal het maximale uit je crawl-budget, verhinder dat bots duplicate content detecteren en dat je server onnodig belast wordt. Als je robots.txt juist inzet, dan kan dat allemaal.
Een goed begrip van robots.txt mag je niet onderschatten. De logica lijkt simpel, en net daar schuilt het gevaar. Ik kom zeer regelmatig implementaties tegen die mijn wenkbrauwen doen fronsen. Van onnodige herhaling, verkeerde syntax, tot regels die gewoon niet werken. En veelal heeft men er gewoon geen weet van. In dit artikel vind je een compilatie en wat je hieraan kan doen, verdeeld in 2 belangrijke SEO-regels.
Regel 1: enkel de meest specifieke User-agent telt
Om dit uit te leggen ga ik twee voorbeelden aanhalen van tiktok.com en twitter.com. Dat zijn niet direct kleine websites. Sterker nog: wereldwijd zijn dit de 15e en 5e meest bezochte websites. We mogen aannemen dat crawl-budget wel een ding is voor hen.
Voordat we in deze twee cases duiken, leg ik uit wat de fout precies is. Ik gebruik hiervoor een simpel codevoorbeeld voor robots.txt:

Kennelijk denken veel mensen dat er overerving is. Simpel gezegd betekent overerving dat je ‘algemene regels’ kan schrijven die voor iedereen gelden, en daarnaast specifieke regels. Oftewel, men denkt bij dit voorbeeld dat alles onder User-agent: * automatisch ook geldt voor Googlebot & Bingbot. Dat is niet zo.
‘User-agent: *‘ betekent namelijk dat je regels gelden voor alle bots. Als je enkel de Googlebot wil aanspreken, dan schrijf je ‘User-agent: Googlebot‘. Men neemt daardoor vaak aan dat je alle gemeenschappelijke regels onder ‘User-agent: *’ kunt plaatsen en enkel de specifieke regels voor Googlebot daar schrijven. Maar zodra je een specifieke Googlebot user-agent vermeldt, kijkt Google enkel nog naar die regels. En dus is alles onder ‘User-agent: *’ niet van toepassing voor Google (in dit geval).
Als je me niet gelooft, dit zegt de robots.txt-tester van Google:
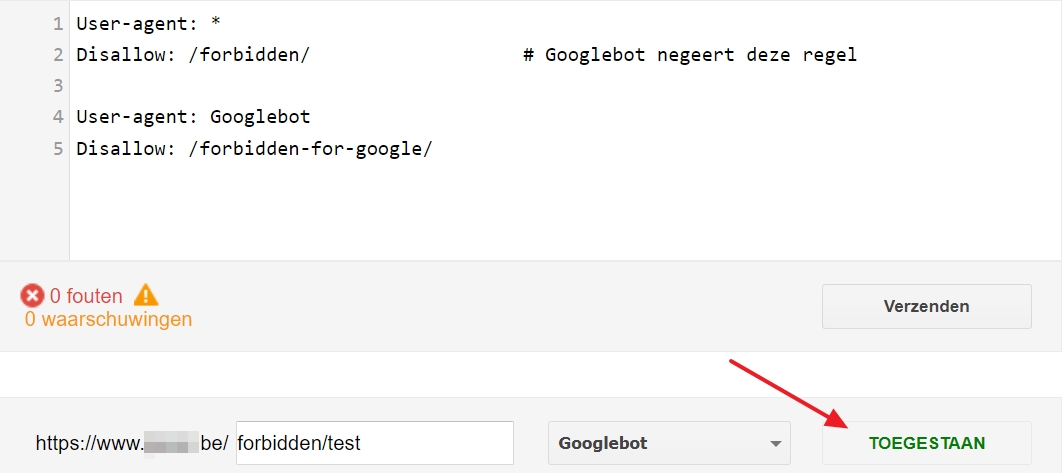
Zoals reeds vermeld: ook grote websites maken deze fout. Ik licht ze hieronder toe.
1. De robots.txt van tiktok.com
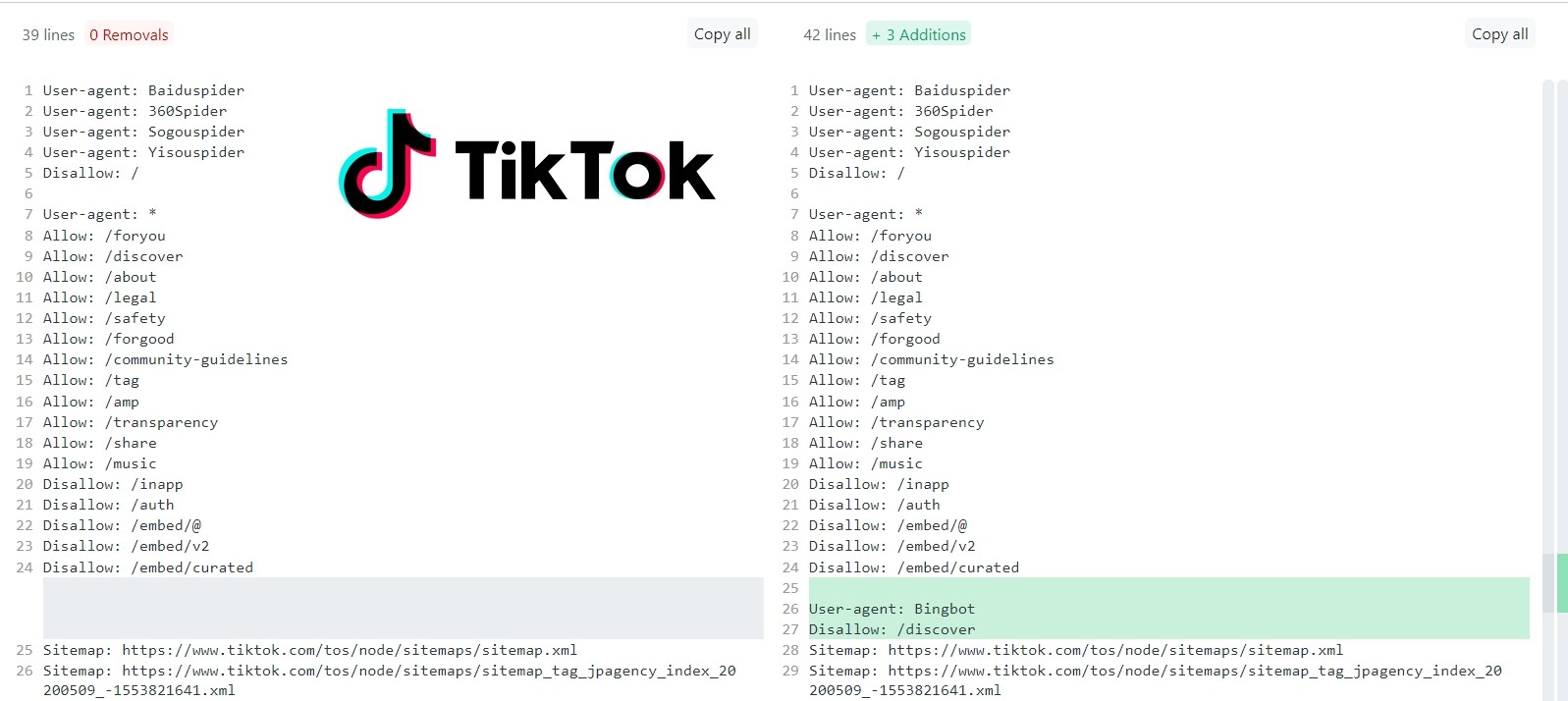
Een fantastisch voorbeeld is de /robots.txt van TikTok, die één dag na de aankondiging van de ChatGPT/Bing integratie BingBot blokkeerde op haar /discover folder.
Wat ze wellicht niet doorhadden: nu zijn alle Disallow-regels onder User-agent: * niet langer geblokkeerd voor BingBot. En dus kan Bing al die URL’s plots wel crawlen. Voor hun crawl-budget is dat niet direct een goede evolutie.
Voor wie zich afvraagt wat de /discover URL’s van TikTok zijn, dat zijn deze links.
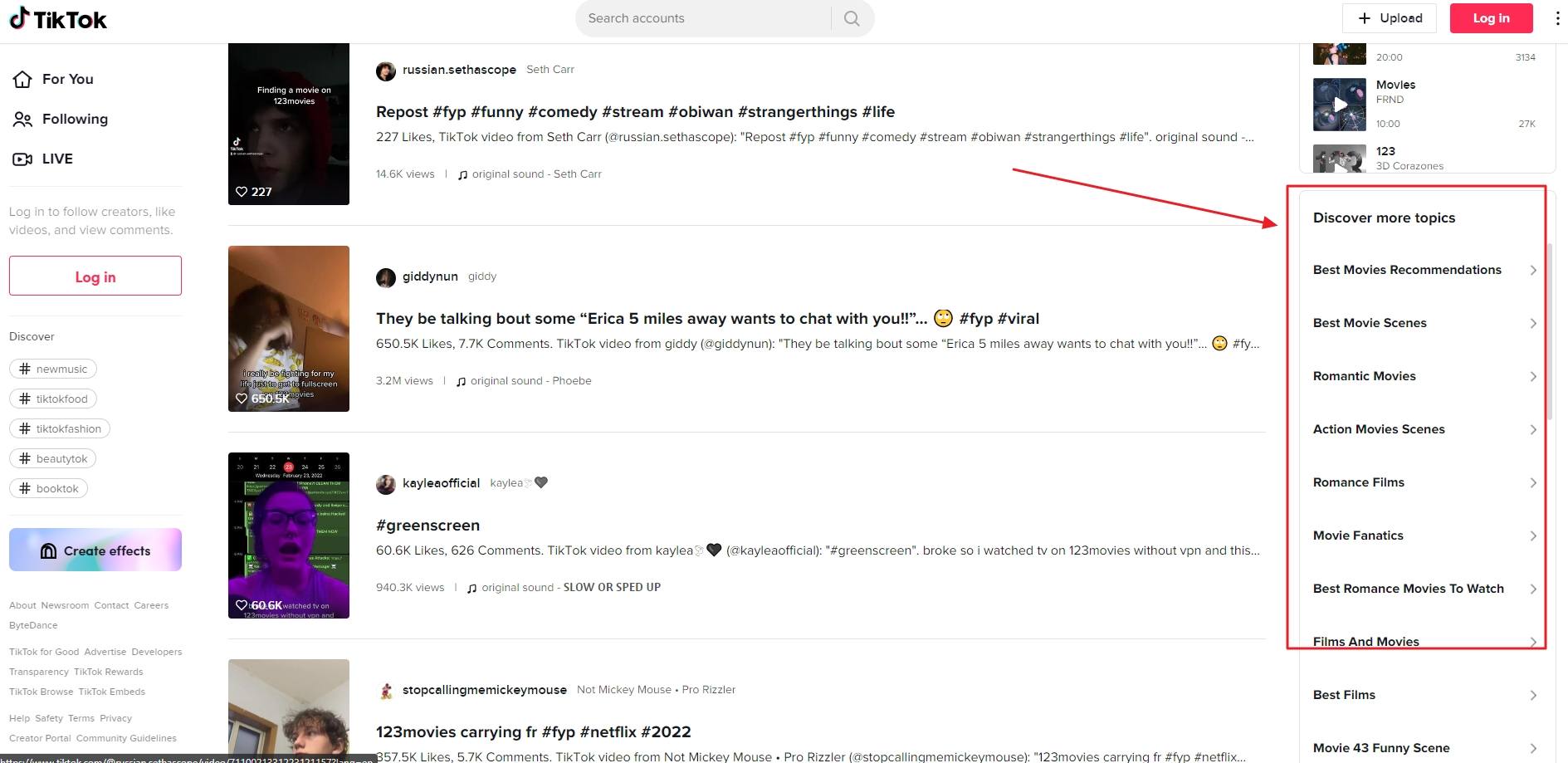
Zoals ik al zei, gooi dit in een robots.txt tester-tool en je ziet dat de URL gecrawld kan worden.

TikTok had dit duidelijk niet door, want iets later voegden ze nog een extra regel toe:
- Disallow: /link
Maar als je de logica die ik eerder beschreef goed begrijpt, dan weet je dat ook deze regel niet van toepassing is voor Bingbot. Ik ben er zeker van dat TikTok dit niet door heeft.
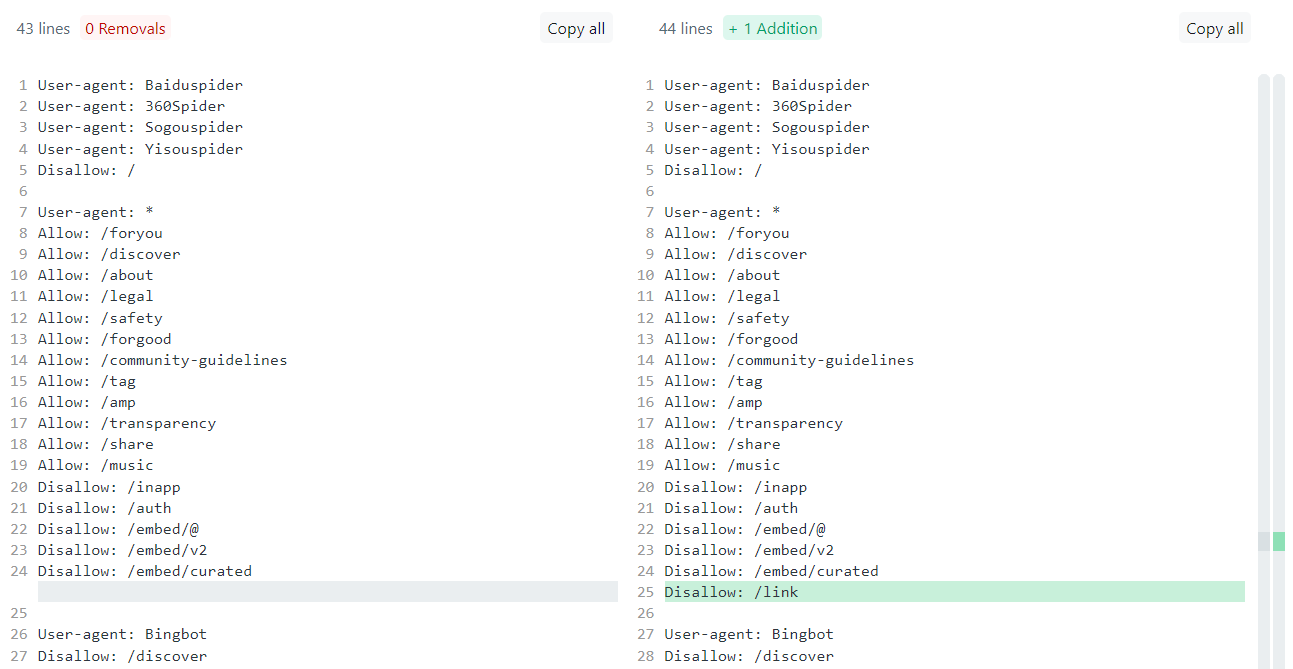
Wat moet TikTok dan feitelijk doen? Wel eigenlijk kunnen ze dit schrijven:

Ja, dit mag gewoon, en dit werkt nu voor alle andere bots en Bingbot. Merk op dat Bingbot nog een tweede keer onderaan vermeld staat met een specifieke regel.
2. De robots.txt van Twitter
En ook Twitter maakt exact dezelfde fout met hun robots.txt bestand. Mocht dit bestand in de toekomst veranderen, dan kan je hier de versie van juli 2023 terugvinden.

Wat je hier ziet?
De regels aangeduid met accolade beschouwt Twitter als uitgesloten voor alle bots. Dit vermelden ze er zelfs expliciet bij via een comment. Maar hoger in hun robots.txt-bestand staan diezelfde regels niét onder Googlebot. Googlebot kan die pagina’s dus gewoon crawlen.
Het betreft deze regels:
- Disallow: /oauth
- Disallow: /1/oauth
- Disallow: /i/streams
- Disallow: /i/hello
- Disallow: /i/u
3. Geluk bij een ongeluk: case via SEO Mastermind
Ik zag recent nog in de SEO Mastermind-community een mooie case van iemand die vragen had bij een toch wel bedenkelijke robots.txt-implementatie. De webbouwer ging het crawlen van JS, CSS en dergelijke blokkeren (geen goed idee!) voor alle bots maar had ook aparte regels voor Googlebot geschreven. Een geluk bij een ongeluk, want daardoor tellen die Disallow-regels niet meer voor Google.

Zo dat was dan regel 1: enkel de meest specifieke User-agent telt. Op naar regel 2.
Regel 2: vermijd onnodige herhaling van regels per User-agent
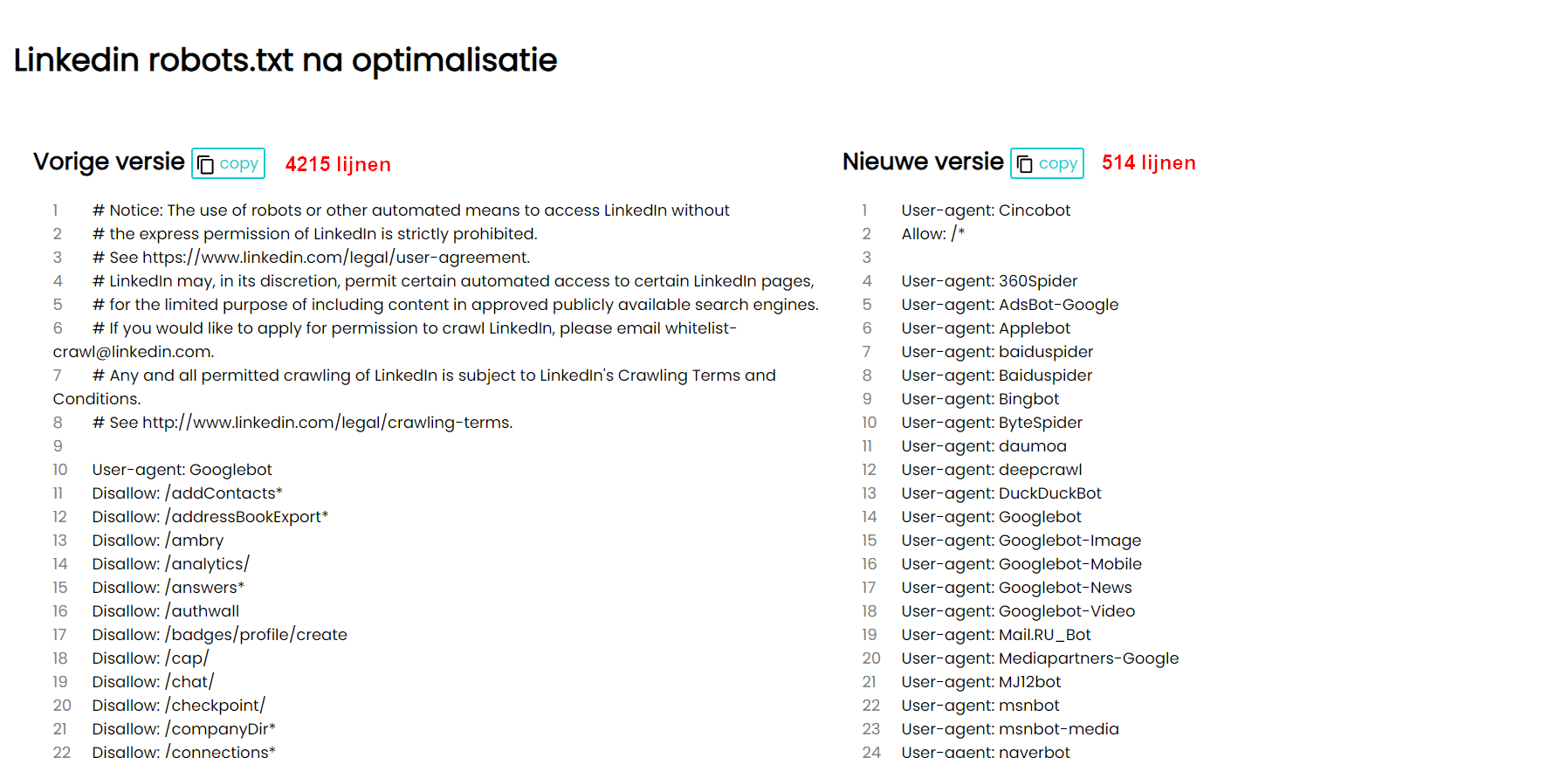
Ik vind het opvallend dat er in de robots.txt van LinkedIn (op moment van schrijven) 4.215 lijnen staan. Ik dacht eerst nog: ‘Da’s een grote website. Het zal nodig zijn zeker.’ Niks blijkt minder waar. Op zich werken de regels wel, dus dat is positief. Maar het is gewoon nodeloos lang, chaotisch en zeer moeilijk om te onderhouden (inefficiënt). Bovendien staat hierdoor de deur open voor fouten, die je tevens moeilijk detecteert.
Alles samen is het toch al een bestand van 100kB. Op zich geen probleem: Google cachet je robots.txt (gelukkig!) voor een bepaalde tijd, dus ze moeten die niet opnieuw opvragen bij élke crawl request. Toch kan je dit niet bepaald efficiënt noemen. Google moet telkens 4.000+ regels verwerken om te controleren wat ze wel/niet mogen crawlen. Bovendien is zo’n wanordelijk bestand heel moeilijk te onderhouden. Iets wat ook blijkt uit mijn analyse van hun regels.
Wat doet LinkedIn verkeerd?
Zoals uit onderstaand screenshot blijkt, schrijft LinkedIn alle regels voor élke user-agent telkens opnieuw, ook als het 100% dezelfde regels zijn (360spider en Sogou bijvoorbeeld).

Kan het dan niet efficiënter?
Natuurlijk wel. Anders maak ik hier geen punt van.
Je kan User-agents met dezelfde regels gewoon samenvoegen. Dat maakt het veel leesbaarder. Onder het screenshot heb ik een voorbeeld van de code geplaatst. Alleen hiermee spaar je al 114 lijnen code uit. Er staan 38 aparte User-agents vermeld in dit bestand, en ik zie dat die exacte 114 lijnen bij alvast 17 User-agents overeenkomen.
Totale uitsparing door deze ene samenvoeging: 1938 lijnen code, oftewel -50%. Voilà.

Maar het kan nog beter. Ik maakte via Google Sheets wat berekeningen om élke disallow/allow-regel telkens maar één keer te vermelden. Ook als de ene user-agent 113 regels heeft, en de andere 114 regels (één specifiek regeltje extra).
Het resultaat is dat ik 4.215 lijnen code ingekort werd tot 514 lijnen code. Je vindt de ingekorte versie hier: https://sitesfy.be/linkedin/robots.txt.
Voor een vergelijking voorr en na optimalisatie, kan je hier kijken: https://sitesfy.be/show/linkedin.
Leuk weetje: Ik deed deze oefening reeds maanden terug, en toen kreeg ik de code ingekort tot exact 300 lijnen. In de tussentijd paste LinkedIn echter wat dingen aan in hun bronbestand, en mijn geoptimaliseerde versie werd plots een stuk langer.
Wat is het voordeel?
Dit alles is véél leesbaarder én beter te onderhouden. Mijn vermoeden is zelfs dat LinkedIn hier wat updates aan dient te doen. Het lijkt namelijk te toevallig dat sommige regels bij net niet alle User-agents staan. Zoals je in de geoptimaliseerde robots.txt zal merken kan je dit plots héél eenvoudig spotten. Zoek maar eens naar deze regel:
Disallow: /slink*
Je zal zien dat die vermeld staat bij 35 User-agents. Hoger in het document staan echter 114 globale regels vermeld bij 36 User-agents. Misschien is LinkedIn ergens een vermelding vergeten?
Andere veelvoorkomende fouten
Ik kom nog heel wat andere interessante fouten tegen in het robots.txt-bestand. Daar wijd ik graag eens in een ander artikel over uit. Voor nu krijg je van mij al een korte samenvatting:
- Blokkeren van URL’s die reeds geïndexeerd zijn.
- Conflicten tussen regels: de meest specifieke regel geldt.
- Foutieve regels schrijven (vaak omdat men de syntax niet kent).
- Regels schrijven die niet alles uitsluiten (vaak met parameters).
- Blokkeren van bronnen die belangrijk zijn voor rendering.
- Robots.txt overschrijven bij nieuwe release (vaak bij Drupal), zonder het te weten.
- De klassieker: volledige website geblokkeerd na migratie.
- Geen monitoring opgezet.
- Een relatieve URL als sitemap vermeld.
Voorkom deze robots.txt fouten
Ik kom heel regelmatig foutieve implementaties van robots.txt tegen. Zoveel diverse fouten zelfs, dat ik ze niet allemaal in dit artikel kon bespreken. De focus lag erop om 2 zeer ingrijpende – doch vaak onbekende – fouten in detail uit te lichten. Enerzijds moet je snappen dat enkel de meest specifieke user-agent van toepassing is. Anderzijds is het belangrijk om je robots.txt leesbaar te houden door user-agents met dezelfde regels te bundelen.
Nu je weet waarom deze fouten zich voordoen, en wat je eraan kan doen, hoop ik dat jij als lezer hier je voordeel mee doet.
Dit artikel is gecheckt door het SEO-panel. Bron header-afbeelding: Diabluses, Diego Thomazini, Alexuans / Shutterstock.com
Over de auteur
