
Structured data: wat is het & wat kun je ermee?


Met structured data kunnen webdevelopers en SEO’ers betekenis en context te geven aan inhoud voor zoekmachines en hun crawlers, waardoor die content op een begrijpelijke manier kan worden weergegeven. In dit artikel beschrijf ik wat structured data is, hoe je dit kunt inzetten, wat het met SEO te maken heeft en welk belang het in de toekomst zou kunnen hebben.
De term structured data is in de eerste plaats een algemene term. Gestructureerde gegevens – het maakt niet uit in welke context – zijn altijd aanwezig wanneer ze een bepaald patroon of formaat volgen, dat wil zeggen: wanneer ze volgens een bepaald schema zijn georganiseerd. Het begrip schema is in dit geval relevant, hier kom ik later nog op terug.
Aangezien zoekmachines te maken hebben met een vrijwel oneindige hoeveelheid aan informatie, ligt de uitdaging in het sorteren en interpreteren van deze gegevens. Pas als de informatie voldoende wordt begrepen, kan dit worden gebruikt bij het zo goed mogelijk beantwoorden van zoekopdrachten. Door structured data hebben websitebeheerders de mogelijkheid zoekmachines te helpen met het begrijpen en interpreteren van hun website en informatie.
Het samenwerkingsproject Schema.org
In 2011 hebben de meest prominente zoekmachines hun krachten gebundeld en het initiatief Schema.org gelanceerd. Inmiddels hebben Google, Yahoo, Bing (Microsoft) en Yandex zich achter dit opensourceproject geschaard. Het doel is ervoor zorgen dat de inhoud van websites uniform wordt gelabeld, zodat zoekmachines deze gemakkelijker kunnen interpreteren.
Schema.org vertegenwoordigt in zekere zin een een ontologie, oftewel een alomvattend conceptueel schema. Alle denkbare entiteiten (dingen), acties en relaties worden hier gecatalogiseerd in de directory, die voor iedereen toegankelijk is op www.schema.org. Als ik bijvoorbeeld boeken verkoop in mijn online shop, kan ik de afzonderlijke productpagina’s markeren, zodat zoekmachines weten: “Dit gaat over [Book]!”
De entiteit [Book] staat meestal voor concrete literaire werken met specifieke kenmerken. Ik kan deze kenmerken in een tweede stap dichter bij de zoekmachines brengen. Ik vul een min of meer uitgebreid masker van properties in, waarbij elke property voor een bepaalde eigenschap staat. Zo ligt het voor de hand om onder andere de titel van het boek, de auteur, het aantal pagina’s, de taal, het ISBN-nummer en de prijs te definiëren.
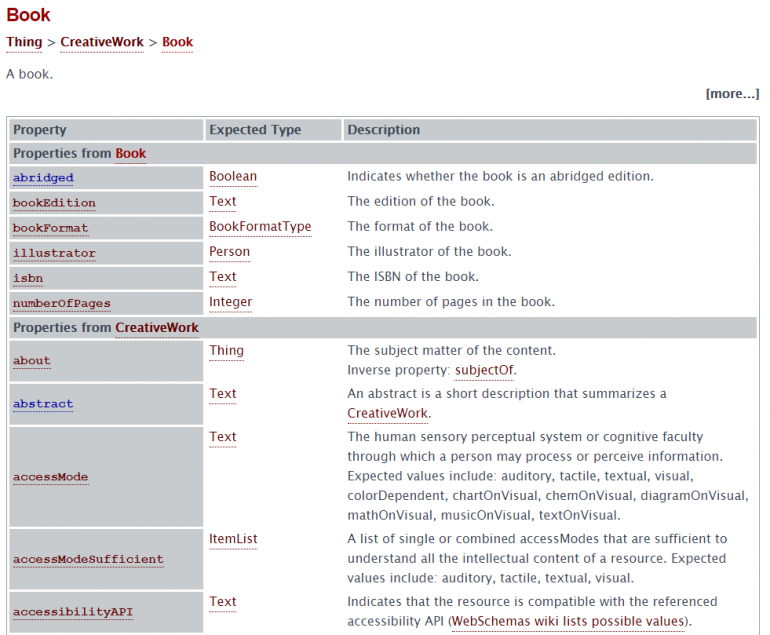
Property van “Book” op Schema.org
Met alleen woordenschat is een taal niet compleet
Met schema.org hebben de grote zoekmachines dus een voortdurend groeiend woordenboek gebouwd. Om hieruit een begrijpelijke taal te creëren, is grammatica nodig, regels die de taal logisch maken. Precies dit wordt aangevuld door de volgende opmaaktalen: JSON-LD, HTML Microdata en RDFa. Elke grammatica werkt anders, maar ze bieden mij als websitebeheerder allemaal de mogelijkheid om met behulp van structured data mijn website begrijpelijker te maken. Wat de voor- en nadelen van deze verschillende talen zijn en wat op dit moment de beste keuze is, bespreek ik later in meer detail.
Wat heb ik als websitebeheerder aan structured data?
Het is natuurlijk fijn voor zoekmachines dat zij de informatie beter begrijpen, maar wat heb ik daar als websitebeheerder nou aan? Het antwoord hierop is visueel sterkere resultaten bij zoekmachines. Deze zogenaamde rich results tonen naar de titel, beschrijving en URL, ook andere elementen zoals review-sterren, breadcrumbs en andere opvallende elementen.
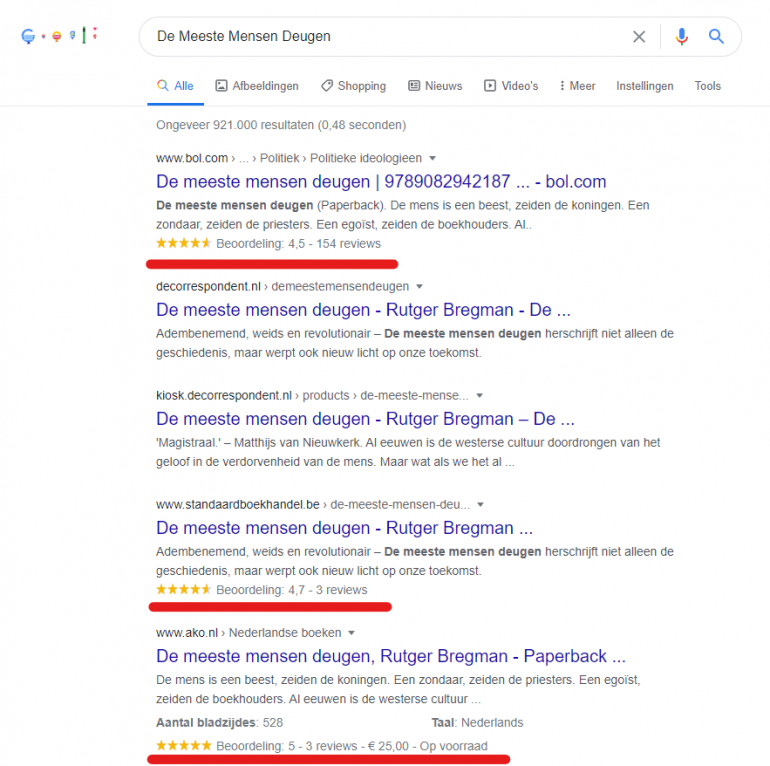
Google-zoekopdracht naar De meeste mensen deugen met normale en rich results
Afbeelding 2 toont een screenshot van een Google-zoekopdracht naar De meeste mensen deugen, het boek van Rutger Bregman. Er valt meteen een verschil op tussen het eerste en tweede resultaat, namelijk de beoordelingssterren en het aantal reviews. Daarnaast toont het eerste resultaat een heldere breadcrumb-structuur. Het beste voorbeeld wordt in dit geval als laatste getoond bij ako.nl, waar ook de prijs en beschikbaarheid worden weergeven. Voor een gebruiker is dit natuurlijk waardevolle informatie, die in ieder geval meer aandacht trekt dan de overige resultaten. Hoewel dit speculatie is, kan het goed zijn dat ako.nl in dit geval een betere CTR heeft dan kiosk.decorrespondent.nl, ondanks dat de laatste een betere positie inneemt.
Rich results
Al deze elementen, dus breadcrumbs, reviews, prijs en beschikbaarheid worden gevoed door structured data. Het komt voor dat pagina’s die zijn voorzien van structured data, deze rich results niet krijgen. Daarentegen: pagina’s die geen gebruik maken van structured data, krijgen deze rich results zeker niet.
Een andere vorm, die vooral ook bij mobiele apparaten belangrijk kan zijn, zijn carrousels. De afbeelding hieronder toont bijvoorbeeld hoe Albert Heijn zijn recept voor boerenkool heeft voorzien van structured data om in deze carrousel te worden opgenomen. Vooral de kans om in dit soort carrousels kliks te verkrijgen, is veel hoger dan in de normale zoekresultaten.
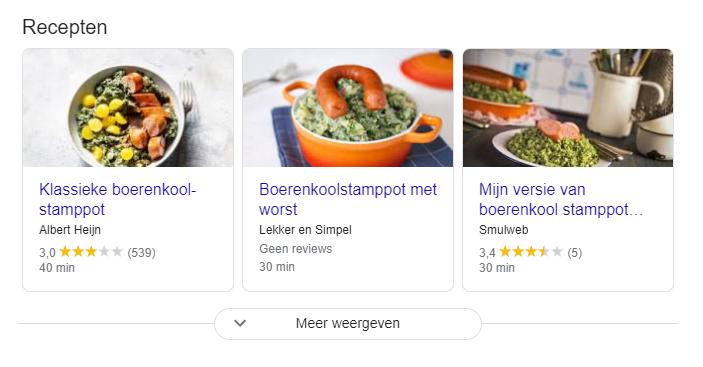
Google-zoekopdracht naar ‘boerenkool recept’ inclusief carrousel
Verwar dit soort carrousels overigens niet met featured snippets, waarbij Google een tabel, lijst of tekstparagraaf een prominente plaats bovenaan de zoekopdracht geeft. Structured data hebben geen invloed op dit soort featured snippets.
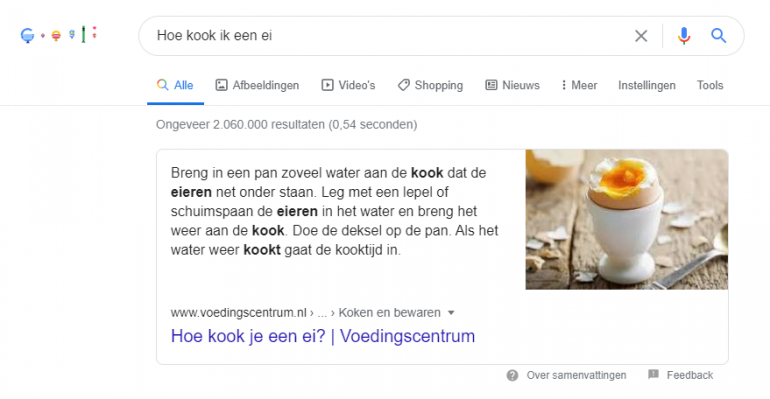
Google-zoekopdracht naar ‘Hoe kook ik een ei’, inclusief featured snippet
Dat Google hier een featured snippet toont van Voedingscentrum.nl, is uitsluitend te danken aan het feit dat Google de inhoud van de pagina zo heeft beoordeeld dat deze het beste en meest beknopte antwoord geeft.
Andere mogelijke manieren om de snippets te verrijken tot rich results met behulp van structured data worden door Google getoond in de Search Gallery.
Hoe implementeer je structured data?
Allereerst kun je onderscheid maken tussen specificaties voor de kwaliteit van de gegevens en voor de technische uitvoering. Een van de kwaliteitseisen voor de inhoud is dat je alleen unieke inhoud mag markeren met structured data. Met andere woorden: alleen inhoud die door mijzelf of door mijn gebruikers is gemaakt, mag ik het markeren. Bovendien moet de gemarkeerde inhoud zichtbaar zijn voor gebruikers. Als je bijvoorbeeld een product van structured data voorziet, dan moet het ook zichtbaar zijn op de site. Ook mag je geen irrelevante of misleidende inhoud markeren. Dit geldt eveneens voor nepreviews of inhoud die niets te maken heeft met de hoofdinhoud van een pagina.
Technisch gezien is het natuurlijk een basisvereiste dat alle inhoud die in de zoekresultaten moet worden weergegeven, toegankelijk is voor zoekmachines en hun bots. Dit betekent dat de toegang niet mag worden geblokkeerd door bijvoorbeeld de robots.txt. Voor de implementatie moet je ook JSON-LD, RDFa of Microdata gebruiken. Om mogelijke fouten en dubbele markeringen te voorkomen, is het aan te bevelen je te beperken tot één van de drie formaten: JSON-LD, RDFa of Microdata.
JSON-LD
JSON-LD (JavaScript Object Notation for Linked Data) is de recentste methode voor het labelen van structured data. Het is ook het formaat dat Google regelmatig aanbeveelt. Een van de grootste voordelen van JSON-LD is dat je het – in tegenstelling tot andere formaten – onafhankelijk van de rest van de broncode van een website kunt integreren. Net als de meta-description is JSON-LD geïmplementeerd in de <head>-sectie, oftewel de header van een HTML-document. Dit maakt het mogelijk om een pagina-template of structured data volledig onafhankelijk van elkaar aan te passen.
RDFa
De implementatie met behulp van RDFa is gebaseerd op een iets andere aanpak. In plaats van het combineren van de structured data in één – ook voor mensen leesbaar – blok zoals in JSON-LD, worden de gegevens verdeeld over de gehele inhoud van een pagina. RDFa zijn ‘HTML5 extensions’: bestaande HTML-elementen worden uitgebreid en voorzien van extra informatie, in dit geval voor het markeren van structured data.
Microdata
HTML-extensies worden ook gebruikt bij Microdata. Microdata wordt echter als verouderd beschouwd en niet meer actief doorontwikkeld. Toch kom ik nog regelmatig websites tegen, ook van klanten, die nog met Microdata werken. Vandaar dat het relevant is deze optie hier nog kort te noemen.
Welke formaat kun je het beste gebruiken?
Heb je nog geen structured data geïmplementeerd? Dan beveel ik het gebruik van JSON-LD aan. Dankzij ondersteuning van Google, Bing (sinds juli 2018) en Baidu is dit formaat nu klaar voor drie van de grote vier zoekmachines. Alleen de Russische zoekmachine Yandex ondersteunt tot nu toe alleen Microdata en RDFa. Mocht er al structured data met behulp van Microdata of RDFa zijn geïmplementeerd, dan kan dit natuurlijk worden gehandhaafd. Er moet echter regelmatig worden gecontroleerd hoe lang de zoekmachines deze twee formaten in de toekomst zullen blijven ondersteunen.
Sommige van de mark-ups hebben aanvullende eisen, die je tijdens de implementering in overweging moet nemen. Deze specifieke richtlijnen staan allemaal in de ‘Feature Guide’ in het Google Developers Portal.
Veelvoorkomende fouten met structured data
Door de vele verschillende richtlijnen kunnen makkelijk bepaalde fouten in de mark-up worden gemaakt. Zelfs de testtool van Google voor gestructureerde gegevens is niet altijd even behulpzaam. Een aantal veelvoorkomende fouten zijn eenvoudig over het hoofd te zien, dus hier een korte samenvatting.
Beoordelingen of recensies (review snippet)
Hoewel het gebruik van widgets (van derden) om beoordelingen of reviews te implementeren over het algemeen geen probleem is, zijn er een paar punten waar je rekening mee moet houden. Het is vooral belangrijk dat de opmaak van de review altijd verwijst naar de hoofdinhoud van een pagina. Een veelgemaakte fout is dat een algemene review van een webshop paginabreed wordt weergegeven via een widget, en dus ook op afzonderlijke productpagina’s te zien is.
Aangezien deze review betrekking heeft op de webshop zelf, en niet op de individuele producten, kan Google dit als spam beschouwen. Daarnaast moeten reviews, die niet afkomstig zijn van de website zelf, altijd een link naar de bron bevatten. Het moet voor gebruikers en zoekmachines dus duidelijk zijn waar deze recensies vandaan komen.
Onzichtbare content voor gebruikers
Gemarkeerde content moet zichtbaar zijn op desktop en mobiele apparaten. De gebruiker moet kunnen herkennen waar de content zich op een bepaalde pagina bevindt, die door een rich result in de zoekmachinepagina’s wordt getoond. De enige optie die je als websitebeheerder hebt, is content achter een tab te plaatsen, die zich voor gebruikers na een muisklik opent. Voorwaarde is natuurlijk wel dat de zoekmachinebot ook de tabbed content kan lezen.
Misleidende of ongeschikte inhoud
Wellicht een open deur, maar de gemarkeerde content moet relevant zijn en passen bij de inhoud van een bepaalde pagina. Bijvoorbeeld, een all-inclusive reis voor een concert van de Foo Fighters kun je niet als event markeren. Het markeren van het concert zelf is daarentegen wel een correcte implementatie van de event mark-up. Wees kortom zo specifiek mogelijk bij het taggen of markeren van structured data.
Is structured data relevant voor SEO?
Een veelgestelde vraag van klanten is hoe relevant structured data voor SEO is. En deze vraag kun je, zoals veel SEO-vragen, beantwoorden met: het hangt ervan af. In de meeste gevallen heeft de implementatie van structured data geen directe invloed op de positie van een pagina in een zoekmachine. Google en co. beoordelen een pagina niet anders als deze met structured data gemarkeerd is. Maar in veel gevallen verhogen rich results de click-through-rate omdat ze meer informatie bieden en de resultaten simpelweg meer opvallen tussen de gewone resultaten. Zoekresultaten met review-sterren springen bijvoorbeeld meer in het oog dan resultaten zonder een dergelijke mark-up. Er is in dit geval dus wel degelijk een indirecte relevantie voor SEO vast te stellen.
Daarnaast heeft John Müller (Senior Webmaster Trends Analyst bij Google) onlangs tijdens een webmaster hangout nog benadrukt, dat zelfs wanneer een bepaald type structured data niet bijdraagt aan het verkrijgen van rich results, het Google toch kan helpen bij het begrijpen van bepaalde content.
Een andere speciale functie zijn de resultaten van artikelen, recepten en enkele andere zoekfuncties. Als de eigen inhoud correct getagd is, heeft die de kans om te worden weergegeven in speciale boxen, zoals de carrousel met recepten. Dergelijke carrousels staan meestal bovenaan op de eerste resultatenpagina – en hoog ranken in Google is uiteindelijk het doel van zoekmachineoptimalisatie.
Tools voor structured data
Gelukkig zijn er voor structured data tal van tools die webmasters kunnen helpen bij de implementatie of zelfs bij het controleren van de gewonnen rich results.
Google’s Codelab
Als dit onderwerp relatief nieuw voor je is, dan helpt Google’s Codelab je al vrij snel op weg. Aan de hand van praktische voorbeelden loop je stap voor stap door de verschillende mogelijkheden. Let op: momenteel is Google’s Codelab voor structured data alleen beschikbaar in het Engels.
Schema Markup Generator
De “Schema Markup Generator (JSON-LD)” van Technicalseo.com is zowel geschikt voor beginners als voor gevorderden. Het bevat alle gebruikelijke mark-ups en je kunt geldige structured data-code met een paar klikken maken.
Rich Result Test Tool
Een van de meest essentiële tools voor het testen van gestructureerde gegevens is de Testtool van Google zelf. Voorheen was dit voornamelijk de Structured Data Testing Tool, maar Google heeft onlangs aangekondigd dat deze tool zal worden opgeheven. Wanneer is nog niet geheel duidelijk, maar Google heeft een vervanging aangeboden in de vorm van de Rich Result Test Tool. Het probleem bij deze aanpassing is dat de Rich Result Testing Tool alleen tests uitvoert op het gebied van rich results, waar de Structured Data Tool ook bepaalde markeringen controleert die (nog) niet tot rich results leiden. Voor veel SEO’ers en webmasters een vervelende ontwikkelingen. De vraag is of er een vervanging zal komen of dat er veranderingen bij de Rich Results Test Tool worden doorgevoerd, waarmee je ook andere structured data-markeringen kunt controleren en valideren.
Javascript bookmark
Voor degenen die vaak verschillende URL’s willen controleren op structured data, is de volgende JavaScript bookmark een goede keuze voor de browser. Hiervoor moet je eerst een nieuwe bladwijzer aangemaken in de browser. In plaats van een URL voer je echter de volgende code in:
javascript:(function(){ window.open('https://search.google.com/structured-data/testing-tool/u/0/#url=g'+encodeURIComponent(location.href))})();
Als je vervolgens naar een pagina surft die je wil controleren op gestructureerde gegevens, hoef je alleen maar op de bladwijzer te klikken. Een nieuw browsertabblad opent onmiddellijk de overeenkomstige URL in de Testtool van Google.
What’s next?
Sinds de introductie van structured data worden er regelmatig nieuwe data types toegevoegd. Wat zich momenteel in een bètafase bevindt en mogelijk in de (nabije) toekomst standaard op schema.org kan worden toegevoegd, vind je hier. Google heeft bijvoorbeeld in augustus 2018 het type speakable content toegevoegd en ondersteunt dit sindsdien. Dit type structured data is bedoeld voor inhoud die spraakassistenten en smart speakers gemakkelijk kunnen voorlezen. Op dit moment is de ‘speakable property’ uitsluitend bedoeld voor uitgevers. Naar verwachting komt dit in de toekomst voor alle websites beschikbaar.
Google breidt in de komende jaren waarschijnlijk het aantal structured data opties uit. Bovendien heeft de opname van structured data niet langer uitsluitend effect op de klassieke zoekresultaten in de Google-zoekresultatenpagina’s, zoals blijkt uit het voorbeeld van ‘speakable content’. Het stelt websites in staat zich in andere zoekgebieden te positioneren en zo hun eigen traffic te vergroten.
Over de auteur
