
Waarom je conclusies uit A/B-testen waarschijnlijk fout zijn


Om je concurrentie voor te blijven is het noodzakelijk om je online uitingen te monitoren, continu te optimaliseren en te personaliseren. A/B-testen zijn onmisbaar om de invloed van aanpassingen te toetsen. Maar om op je conclusies te kunnen vertrouwen is het belangrijk dat je de data waarop ze gebaseerd zijn op de juiste manier verzamelt, opslaat en interpreteert. Helaas is dit minder eenvoudig dan het lijkt en gaat dit nog vaak fout. Hierdoor zou het zomaar kunnen dat veel resultaten van A/B-testen niet het juiste verhaal vertellen.
Op het moment dat je een bestelformulier wil verbeteren, kun je gebruikmaken van experimenten om te testen of een alternatieve variant beter is dan het origineel. Een experiment om verschillende varianten of personalisaties te vergelijken, noem je een A/B-test. Een A/B-test is het statistisch verantwoord experimenteren met verschillende versies (varianten) van (onderdelen van) de website. Zo’n experiment voer je uit door het verkeer op de website te verdelen over de varianten en te analyseren welke variant het beste presteert.
Statistieken als graadmeter en als controle
De analyse baseer je op een of meer statistieken die relevant zijn voor het doel van het experiment. Vaak gebruik je één statistiek als graadmeter, bijvoorbeeld het conversiepercentage, en gebruik je andere statistieken, bijvoorbeeld de gemiddelde omzet, als extra controle.
Een resultaat voor een experiment zou er bijvoorbeeld als volgt uit kunnen zien.
| Variant | Gebruikers | Conversiepercentage | Kans om het origineel te verslaan |
|---|---|---|---|
| A (origineel) | 10.000 | 1,00% | - |
| B | 10.000 | 1,28% | 97% |
Bovenstaande tabel is het resultaat van een A/B-test. Met behulp van een tool als A/B Test Calculator kun je op basis van bovenstaande gegevens berekenen of variant B statistisch significant beter is dan het origineel. Hieruit blijkt dat B met een zekerheid van 97 procent beter is dan A. Oftewel, de kans dat B niet beter is dan A, maar toevallig wel beter scoort in de test, is 3 procent. Over het algemeen accepteren we dat als deze kans kleiner is dan 5 procent, dat je resultaat dan statistisch significant is.
De betrouwbaarheid van je data
Op basis van bovenstaand resultaat zou je kunnen besluiten om variant B in te bouwen in je website, zodat iedereen voortaan de verbeterde versie van de website gaat gebruiken. Deze beslissingen kunnen grote gevolgen hebben, vooral naarmate de volumes groter zijn. Je wil dan kunnen vertrouwen op je data. De betrouwbaarheid van je data is afhankelijk van de verzameling, opslag en interpretatie. Het correct verzamelen, opslaan en interpreteren is van groot belang. Ik ga dieper in op de verzameling en opslag van data. Je zult zien welke valkuilen er zijn en wat de correcte manier van verzameling en opslag is.
Segmenteren en uitsplitsen van resultaten
Standaard A/B-testpakketten zijn handig om de inrichting van experimenten te vergemakkelijken, maar de analysemogelijkheden in deze pakketten volstaan in veel gevallen niet. Met name omdat het segmenteren van de resultaten tekortschiet. Dit kan leiden tot verkeerde of onvolledige conclusies. Het kan zijn dat een variant over het algemeen slechter presteert dan het origineel, maar dat er andere resultaten uitkomen als je de resultaten zou opsplitsen. Als je bijvoorbeeld per apparaatcategorie zou opsplitsen, dan zie je dat de variant op mobiel en tablet veel beter presteert en alleen op desktop achter blijft. Het segmenteren en uitsplitsen van de resultaten van A/B-testen creëert meer inzichten en daarmee meer waarde. Helaas zijn deze waardevolle inzichten dus niet te verkrijgen binnen standaard A/B-testpakketten.
Scoping: welke data hoort bij een experiment?
Om deze waardevolle inzichten te krijgen, kun je gebruikmaken van een webanalytics-pakket, zoals Google Analytics of Adobe Analytics. Het meetbaar maken van experimenten is echter niet eenvoudig – je maakt al snel fouten. Helaas ook bij de standaardintegraties. Deze fouten hebben vaak te maken met de toepassing van scoping. In de context van experimenten heeft scoping vooral te maken met de vraag: welke data hoort bij een experiment?
Het is de bedoeling dat de interacties die een gebruiker heeft, vanaf het moment dat de gebruiker in een experiment komt tot het einde van een experiment gekoppeld, worden aan dat specifieke experiment. Op die manier heb je de zuiverste data. Om dit te realiseren dien je de data op de juiste manier te verzamelen. Helaas gebeurt dit vaak niet bij de standaardintegraties tussen A/B-testpakketten en webanalytics-pakketten.
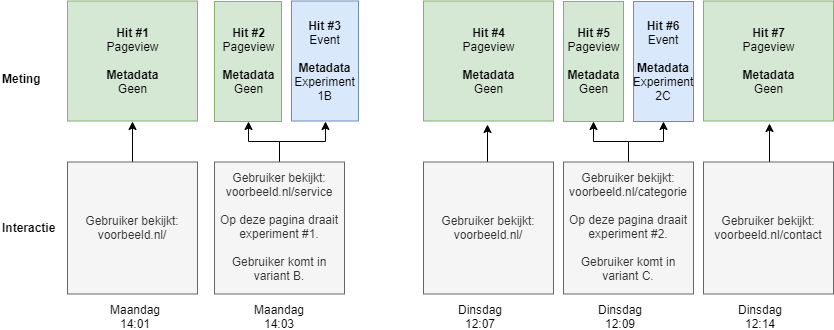
Dit is het makkelijkst uit te leggen aan de hand van een voorbeeld.
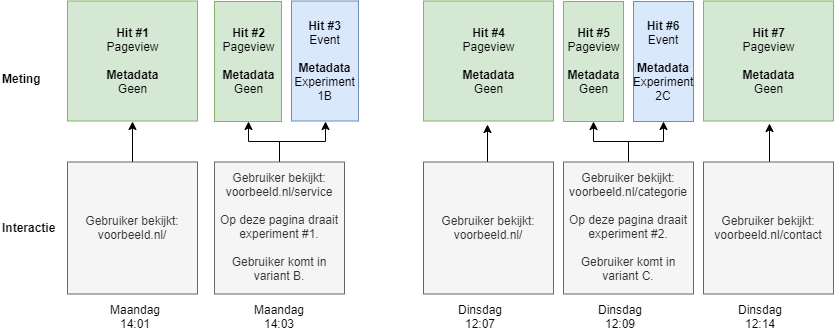
In bovenstaand voorbeeld gaat een gebruiker op maandag en dinsdag naar de website. Op maandag komt hij op de voorbeeld.nl/service pagina en belandt daar in experiment 1B. Vervolgens komt hij op dinsdag weer terug en op de pagina voorbeeld.nl/categorie komt hij in experiment 2C. Op elke pagina wordt standaard een pageview gemeten. Daarnaast stuurt het A/B-testpakket een event op het moment dat een gebruiker in een experiment terecht komt.
A/B-testen analyseren met segmenten of dimensies
In webanalytics-pakketten kun je deze data nu op twee manieren analyseren: met behulp van segmenten of dimensies. De toepassing van segmenten en dimensies is gebaseerd op de scope van data. De scope van data geeft aan welke interacties gekoppeld worden aan de waarde van een dimensie.
Een voorbeeld van een hit-scope dimensie is ‘pagina-URL’. Bij elke interactie wordt deze meegestuurd, omdat elke interactie op een andere pagina zou kunnen zijn. De waarde van de dimensie ‘verkeersbron’ is alleen bekend aan het begin van een sessie. Toch wil je alle interacties gedurende de sessie koppelen aan deze verkeersbron. Dit kan omdat er per sessie slechts één verkeersbron is en we daarom de scope ‘sessie’ kunnen gebruiken. Hetzelfde geldt voor een dimensie met scope ‘gebruiker. Een gebruiker heeft maar één woonplaats. Dat betekent dat als we ergens tijdens zijn klantreis achterhalen wat zijn woonplaats is, we alle interacties kunnen koppelen aan die specifieke woonplaats.
Scoping bij segmenten
Segmenten maken gebruik van scope om selecties te maken van gebruikers en sessies. Deze selecties maak je, omdat je niet over de hele dataset een analyse wil doen, maar van een gedeelte hiervan: het segment. Feitelijk zeg je: ik wil een analyse doen van alle sessies of gebruikers die voldoen aan een bepaalde voorwaarde.
Stel dat we in het voorbeeld hierboven segmenten willen gebruiken. Dan zijn we, afhankelijk van welk experiment we willen analyseren, op zoek naar een segment, dat voldoet aan de voorwaarde dat een sessie of gebruiker in aanraking geweest is met een bepaald experiment.
Als we kiezen voor de scope ‘sessie’ en experiment 1 willen analyseren, dan wordt bij het segmenteren sessie #1 gematcht en vallen de interacties 1 tot en met 3 in het segment. Je ziet direct dat dit niet klopt. We willen interactie #1 namelijk niet relateren aan het experiment.
Een ander voorbeeld kunnen we geven door te kiezen voor de scope ‘gebruiker’ en experiment 2. Bij deze selectie wordt gebruiker #1 gematcht en vallen alle 7 interacties binnen het segment. Dit terwijl interactie 1 tot en met 4 voorafgingen aan het experiment. Ook hier is duidelijk dat deze selectie incorrect is.
Het gaat hier vooral mis, omdat de verkeerde scope gekozen wordt. De keuze voor gebruiker of sessie komt niet overeen met het experiment. De data wordt daarom aan de verkeerde entiteit gekoppeld en dat levert foutieve data op.
| Segment | Gebruikers | Pageviews |
|---|---|---|
| Sessie: 1B | 1 | 2 |
| Gebruiker: 2C | 1 | 5 |
Scoping bij dimensies
Niet alleen bij segmenten, maar ook bij het gebruik van dimensies is scoping een probleem. Dimensies zijn extra variabelen die je meestuurt met een event. Op basis van deze variabelen kun je je statistieken vervolgens opsplitsen. Bijvoorbeeld het aantal pageviews per variant van een experiment. Als je gebruikmaakt van dimensies, dan is het verplicht om tijdens de configuratie een scope te kiezen. De waarde van de dimensie wordt dan gekoppeld aan de scope. Een dimensie kan voor elke scope slechts één waarde hebben. Als gebruiker heb je bijvoorbeeld maar één schoenmaat en als sessie maar één verkeersbron. Op het moment dat je een tweede waarde verstuurd, dan wordt de eerdere waarde overschreven. Je kunt namelijk niet twee schoenmaten hebben. De laatste waarde is dan de waarde die gekoppeld blijft aan de gebruiker of de sessie.
Deze overschrijving is een goede indicatie om te bepalen of je de juiste scope hebt. Op het moment dat het niet logisch is dat op een bepaald niveau slechts één waarde mogelijk is, dan heb je een te brede scope gepakt. Op het moment dat je een dimensie op gebruiker scope kiest voor een experiment, dan zul je zien dat bij het hergebruiken van de dimensie, je de historische data van een vorig experiment kwijt bent. Een duidelijke indicatie dat de gebruiker scope niet de juiste scope is.
Gebruiker als scope
Naast de gevolgen van overschrijving, heeft de keuze van scope ook een andere invloed op de resultaten. Als we de scope ‘gebruiker’ kiezen, dan kun je slechts 1 experiment koppelen aan die dimensie per gebruiker. Dit betekent in bovenstaand voorbeeld dat alle interacties van de gebruiker gekoppeld worden aan variant 2C, vanwege het overschrijven van de eerdere waarde 1B. Dit is duidelijk niet de bedoeling. Niet alleen ontbreekt de data voor variant 1B, maar ook worden interacties die plaatsvonden voordat de gebruiker met in aanraking kwam met variant 2C, aan variant 2C gekoppeld. In onderstaande tabel en diagram zie je de resultaten op het moment dat we de scope ‘gebruiker’ zouden kiezen. De paarse kleur geeft aan welke interacties nu gekoppeld worden aan variant 2C.
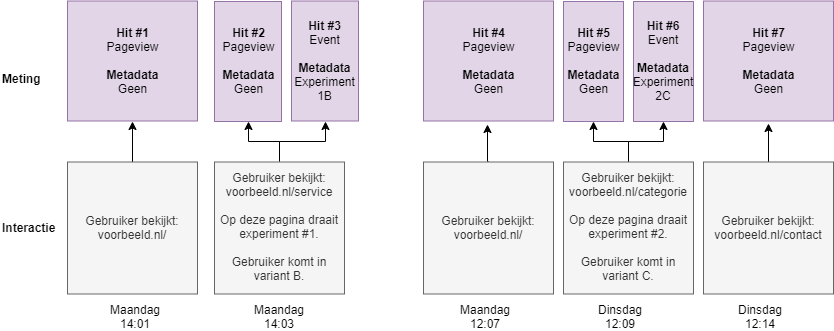
| Variant | Gebruikers | Pageviews |
|---|---|---|
| 1B | 1 | 0 |
| 2C | 1 | 5 |
Sessie als scope
Een andere optie is het gebruikmaken van de scope ‘sessie’. Op dat moment kan er slechts 1 experiment per sessie gekoppeld worden. Dit zorgt er voor dat alle interacties van sessie 1 gekoppeld worden aan variant 1B en worden de interacties van sessie 2 gekoppeld aan variant 2C. Ook hier geldt dat er meer interacties gekoppeld worden dan de bedoeling is. Daarnaast zul je hier ook problemen krijgen op het moment dat één sessie meerdere experimenten raakt. In onderstaande tabel en diagram zie je de resultaten op het moment dat we de sessie scope zouden kiezen. De gele kleur geeft aan welke interacties nu bij variant 1B horen.
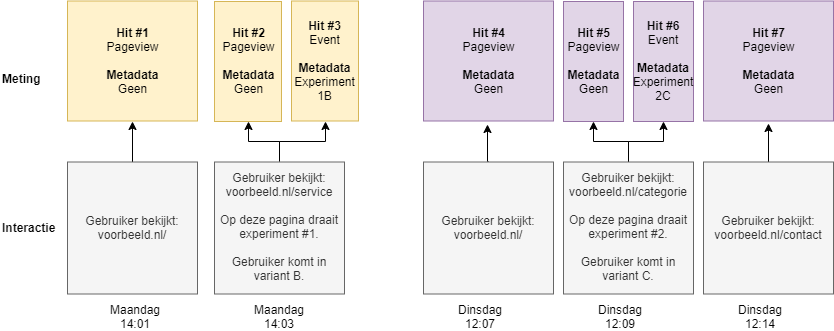
| Variant | Gebruikers | Pageviews |
|---|---|---|
| 1B | 1 | 2 |
| 2C | 1 | 3 |
Hit als scope
Tot slot is er de optie om te kiezen voor de scope hit. Hierbij wordt echter geen enkele pageview gekoppeld aan een variant, omdat de data over de experimenten niet beschikbaar is in die interacties. In onderstaande tabel zie je de resultaten op het moment dat we de hit scope zouden kiezen.
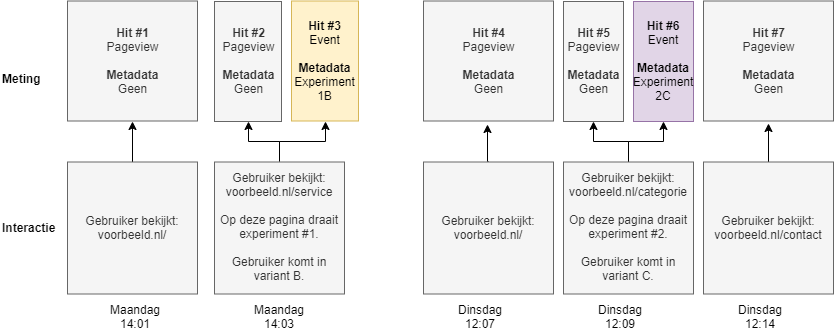
| Variant | Gebruikers | Pageviews |
|---|---|---|
| 1B | 1 | 0 |
| 2C | 1 | 0 |
Hoe je het ook wendt of keert, zowel segmenten als dimensies werken niet als je de data op de verkeerde manier verzamelt. Segmenten en dimensies met de scope ‘gebruiker’ of ‘sessie’ zijn namelijk te breed voor experimenten en zorgen ervoor dat er te veel data gekoppeld wordt aan een experiment.
Onbetrouwbare resultaten
De gevolgen van het verkeerd toepassen van scope verschilt per experiment. Bij sommige experimenten is het verschil klein, terwijl bij andere experimenten het het verschil maakt tussen een significante verbetering of niet. Het bepalen van de impact is alleen mogelijk op het moment dat je ook de correcte data hebt. Dit betekent dat je met uitsluitend een incorrecte scope dus nooit zeker weet of er wel of geen effect is. Deze onzekerheid heeft als gevolg dat je resultaten niet betrouwbaar zijn.
De oplossing
De oplossing is het correct verzamelen van de data en het gebruik maken van een hit-scope. Met elke interactie zul je mee moeten geven welk experiment op dat moment actief is. Als je dat doet, kun je namelijk voor de scope ‘hit’ kiezen en zorg je ervoor dat je geen data koppelt die je niet zou moeten koppelen.
Vaak bieden de standaardintegraties deze mogelijkheid niet. Je moet deze integratie dan zelf maken. Je kunt dit doen door de Javascript API’s of cookies van de A/B-testpakketten te gebruiken. Ook kun je zelf in een cookie bij gaan houden welk experiment op dit moment actief is voor de gebruiker. Voordat je data verstuurt, controleer je dan de actieve experimenten en verrijk je de data van de interactie met de informatie over de actieve experimenten. In ruil voor een complexere inrichting, krijg je correcte data, die je kunt opslaan in dimensies met de scope ‘hit’.
Een laatste keuze
In bovenstaand voorbeeld sturen we met elk event de relevante informatie mee. Dat zorgt ervoor dat we kunnen kiezen voor de scope ‘hit’. In onze rapporten zullen we zien dat alle interacties vanaf hit #2 gekoppeld zijn aan variant 1B en de interacties vanaf hit #4 gekoppeld zijn aan variant 1B en 2C. Dit leidt echter tot een laatste keuze. Gebruik je één dimensie voor alle experimenten of gebruik je voor elk experiment een eigen dimensie?
Er is een nadeel aan alles in één dimensie opslaan. Het is dan niet mogelijk om een mooi overzicht te genereren per experiment. De waardes in de dimensie kunnen namelijk een combinatie van varianten van verschillende experimenten bevatten, zoals in dit voorbeeld 1B en 2C de waarde is vanaf hit #4. Deze varianten worden dan komma-gescheiden in één dimensie gezet. Het voordeel is dat je niet voor elk gelijktijdig experiment een nieuwe dimensie hoeft aan te maken. Kies je voor één dimensie, dan ben je meer tijd kwijt bij de analyse en minder tijd kwijt bij het verzamelen van de data.
Kies je voor een dimensie per experiment, dan is het voordeel dat je eenvoudig een rapport kunt maken per experiment. Het nadeel is dat je voor elk gelijktijdig experiment een aparte dimensie moet aanmaken. Kies je voor een dimensie per experiment, dan ben je meer tijd kwijt aan het verzamelen van data en minder tijd kwijt aan het analyseren van de data.
De wensen van de specialist
Al met al komt het er dus op neer dat in de gebruiksvriendelijkste oplossing (de A/B-testpakketten) de analysemogelijkheden niet voldoen aan de wensen van de specialist. Er wordt dan vaak uitgeweken naar webanalytics-pakketten door gebruik te maken van ‘prebuild’ integraties. Helaas zorgt een beperkt begrip van scoping hier vaak voor incorrecte of misleidende resultaten. De enige mogelijkheid om betrouwbare resultaten in webanalytics-pakketten te krijgen, is bewerkelijk en lastig schaalbaar, omdat het custom Javascript en (her)gebruiken van dimensies omvat. Daarnaast zijn de statistische analyses in de webanalytics-pakketten zelf vaak niet mogelijk, waardoor je alsnog moet uitwijken naar een andere tool.
De vraag is natuurlijk: hoe los je dit op een snelle en schaalbare manier op? Je kunt dit doen door eenmalig de correcte dataverzameling te (laten) implementeren en dit te combineren met een tool die je in staat stelt om A/B-testdata geautomatiseerd te verwerken. Deze tool zou ook moeten zorgen voor een automatische statistische analyse en vervolgens de resultaten helder moeten presenteren in een centraal dashboard. Hierdoor kun je je weer focussen op het experimenteren.
In de praktijk zul je hier een tool voor nodig hebben die je toegang geeft tot de ruwe online data. Dus de losse events die bij elke interactie van de gebruiker met de website verstuurd worden (of in ieder geval de data die gegenereerd worden binnen de experimenten). Hierdoor wordt elke statistische analyse mogelijk (niet alleen op conversiepercentages) en kan elke gevraagde statistiek in een dashboard geplaatst worden. Het kost vaak even een (beperkte) investering aan tijd en geld, maar het is het dubbel en dwars waard.
Headerfoto: Emiliano Vittoriosi via Unsplash.
Over de auteur
