
4 opmerkelijke feiten over deep learning


Het deep learning-algoritme is een bijzondere. Het algoritme kan, zelfstandig, nieuwe vaardigheden leren. De werking ervan is geïnspireerd op de werking van het menselijk brein. Met als gevolg dat het leerproces van het algoritme niet onderworpen is aan theoretische limitaties. Hoe meer ‘computation’-tijd je het geeft, hoe beter het algoritme wordt. Waar is deep learning anno 2015 toe in staat? Vier opmerkelijke feiten over deep learning.
1. Computers kunnen luisteren en praten
Richard Rashid, Senior Vice President bij Microsoft en deep learning-specialist, gaf tot 2012 leiding aan het Microsoft wetenschappelijk centrum. Zijn team richtte zich op deep learning. In 2012, op een Chinese conferentie, toonde hij de wereld een revolutionaire ontdekking. Het door hem ontwikkelde deep learning-systeem kon hem verstaan. En niet alleen dat, maar het systeem wist zijn woorden ook nog eens te vertalen naar het Chinees en dit uit te spreken. Dit deed het systeem onmiddellijk. Allemaal door deep learning-algoritmes.

Hoe heeft het algoritme zich de Chinese en de Engelse taal eigen gemaakt? Rashid legt uit: ‘We’ve been able to take a large amount of information from many Chinese speakers and produce a text-to-speech system that takes Chinese text and converts it into Chinese language.’
2. Computers kunnen zien
Nog indrukwekkender is dat deep learning-systemen kunnen zien. In 2011 vond de ‘German Traffic Sign Recognition Benchmark’ plaats, een competitie waar werd gekeken welk algoritme het beste is in het herkennen van verkeersborden. Het deep learning-algoritme bleek het best. Bovendien was het twee keer zo goed in het herkennen van verkeersborden dan mensen.
In 2012 werd nog eens bevestigd dat deep learning-systemen structuren kunnen herkennen. Geoffrey Hinton, een deep learning-guru en professor aan de universiteit van Toronto, won met zijn deep learnin- algoritme de ImageNet-competitie. Het deep learning-algoritme bleek ten opzichte van andere algoritmes het beste te in het herkennen van 1,5 miljoen afbeeldingen. En het had veruit het kleinste foutpercentage, namelijk 6 procent. Dit is een kleiner foutpercentage dan dat bij mensen is geconstateerd.
Blije mensen herkennen
Jeremy Howard, data-wetenschapper en entrepreneur, geeft in zijn Ted-talk een demonstratie van deep learning. Terwijl hij de zoekopdracht ‘blije mensen’ invoert, genereert zijn deep learning-systeem afbeeldingen van blije mensen. Nu zul je je afvragen wat hier nu precies revolutionair aan is, want Google kan dit toch ook? Maar afbeeldingen zoeken via Google is wezenlijk anders: Google’s algoritmes genereren afbeeldingen door te kijken naar de beschrijvingen die bij de plaatjes horen, terwijl het deep learning-algoritme snapt welke structuren er bij de gevraagde zoekopdrachten horen. Het algoritme herkent de afbeeldingen met deze structuren.

3. Computers kunnen schrijven
Howard gaat in zijn presentatie nog een stap verder. Niet alleen kan het deep learning-algoritme structuren herkennen, het algoritme kan ook nog eens structuren beschrijven: ‘This algorithm before has never seen a man in a black shirt playing guitar. It’s seen a man before, it’s seen black before, it’s seen a guitar before, but it has independently generated this novel description of this picture.’ Het algoritme kan dus eigenhandig bepaalde structuren classificeren.
4. Nieuw wapen tegen kanker
Doordat het deep learning-algoritme structuren kan herkennen en classificeren, is het een waardevol instrument aan het worden in de strijd tegen kanker. Howard licht dat toe: In Boston heeft een team specialisten op het gebied van radiologie het algoritme ingezet om miljoenen afbeeldingen van tumoren te analyseren. Uit de analyse van het algoritme kwamen tientallen nieuwe klinisch relevante eigenschappen van tumoren voort. Met als gevolg dat radiologen veel meer mogelijkheden hebben om tumoren in een vroeg stadium te ontdekken.
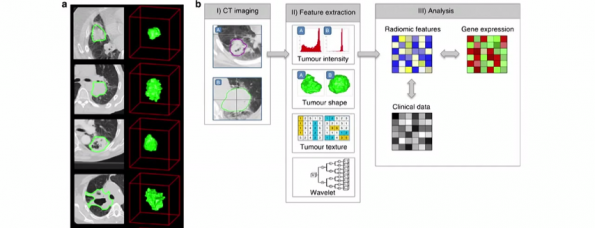
Op het gebied van pathologie is door het gebruik van deep learning een andere waardevolle ontdekking gedaan. Het blijkt dat de cellen rondom kankercellen net zo belangrijk zijn in het diagnosticeren van kanker als de kankercellen zelf. Dit is het tegenovergestelde van wat medische specialisten de afgelopen tien jaar geleerd is, vertelt Howard.
Geen medische expertise nodig
Howard zag in dat al deze doorbraken, op het gebied van kankeronderzoek, werden behaald zonder dat enige medische expertise nodig was. Dit zette Howard aan tot de oprichting van het bedrijf Enlitic, dat als doel heeft het deep learning-algoritme te gebruiken om sneller tot een medische diagnose te komen. Het algoritme wordt gebruikt om miljoenen medische structuren te herkennen en te classificeren.
https://www.slideshare.net/ThomasBrons/stap-1-46325365
97% van de 1,5 miljoen afbeeldingen in 15 minuten
In zijn Ted-talk laat Howard dit zien aan de hand van een voorbeeld, waarbij Howard 1,5 miljoen afbeeldingen van auto’s classificeert. Het algoritme heeft deze afbeeldingen nog niet eerder ‘gezien’. In de presentatie is te zien hoe het algoritme onmiddellijk de structuren herkent. Vervolgens geeft Howard aan welke gebieden het deep learning-algoritme als eerste moet classificeren: ‘These deep learning systems actually are in 16,000-dimensional space, so the computer rotates through that space, trying to find new areas of structure.’ Stapsgewijs geeft Howard het algoritme instructies. Zodat het ontzettend snel, van 1,5 miljoen afbeeldingen, bepaalde groepen structuren kan classificeren. Na 15 minuten heeft Howard 97 procent geclassificeerd. Dit is revolutionair. Want nog niet zo heel lang geleden kostte het classificeren van 1,5 miljoen structuren een team van vijf a zes man, ongeveer zeven jaar lang.
Een groot deel van de medische diagnose kan het deep learning-algoritme op zich nemen. Een deep learning-systeem kan steeds meer structuren herkennen, wat dokters veel tijd kan besparen. Howard vertelt: ‘You can imagine in a diagnostic test this would be a pathologist identifying areas of pathosis, for example, or a radiologist indicating potentially troublesome nodules.’
De mogelijkheden van deep learning lijken onbeperkt
Kortom, het deep learning algoritme is in staat zeer complexe menselijke taken uit te voeren, zoals het vaststellen van medische diagnoses. De mogelijkheden van deep learning lijken onbeperkt. Heeft dit, of gaat dit invloed hebben op de samenleving zoals wij die kennen?
Howard wijst tijdens zijn Ted-talk op een interessant gegeven: voor de uitvoering van 80 procent van alle diensten die wereldwijd worden aangeboden, zijn arbeidskrachten nodig. Onder diensten kunnen we van alles verstaan. Denk aan het aanbieden van vervoer, het bereiden van eten, het vaststellen van een medische diagnose of het vinden van juridische precedenten. Al deze diensten hebben bepaalde vaardigheden gemeen. Vaardigheden als lezen, schrijven, praten, luisteren, waarnemen en het integreren van kennis in de dienstverlening. Dit zijn de vaardigheden die systemen zich eigen hebben gemaakt door de werking van het deep learning-algoritme.
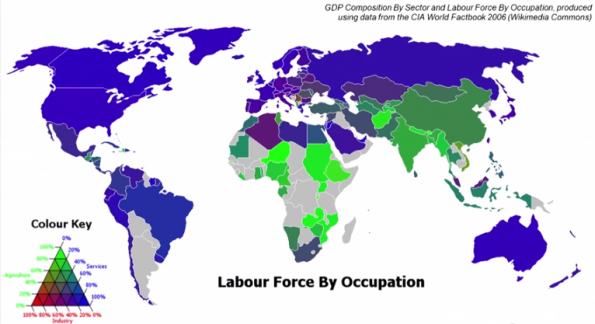
In het blauw de diensten waarvoor arbeidskrachten nodig zijn.
Gevolgen voor de werkgelegenheid
Komt de werkgelegenheid, die al die diensten met zich meebrengen, in ‘gevaar’? Volgens Howard is dit een reële gedachte. Want de ontwikkeling die deep learning zal doormaken is exponentieel van aard: ‘The better computers get at intellectual activities, the more they can build better computers to be better at intellectual capabilities.’
De arbeidsproductiviteit is afgelopen 25 jaar gestagneerd
De gevolgen zijn nu al merkbaar. Zo is de afgelopen 25 jaar de arbeidsproductiviteit, de gemiddelde productie per werknemer gedurende een bepaalde periode, gestagneerd. De arbeidsproductiviteit is zelfs verminderd. Dit terwijl de kapitaalsproductie, productie per eenheid kapitaal per tijdseenheid, is toegenomen.
Schaarste zal niet langer een issue zijn
Wat betekent dit? Computers zijn steeds meer in staat om taken van mensen op te pakken. Er worden op een steeds efficiëntere manier goederen geproduceerd en diensten verleend. Terwijl de productiviteit van een werknemer niet toeneemt. Je zou voorzichtig kunnen zeggen dat schaarste niet langer een issue meer zal zijn. En dat als gevolg daarvan de waarde van een werknemer minder zal worden. Howard stelt dus terecht het punt, dat we moeten kijken naar hoe we onze sociale structuren en economische structuren kunnen aanpassen aan deze nieuwe realiteit.
Illustratie intro met dank aan Fotolia.
Over de auteur